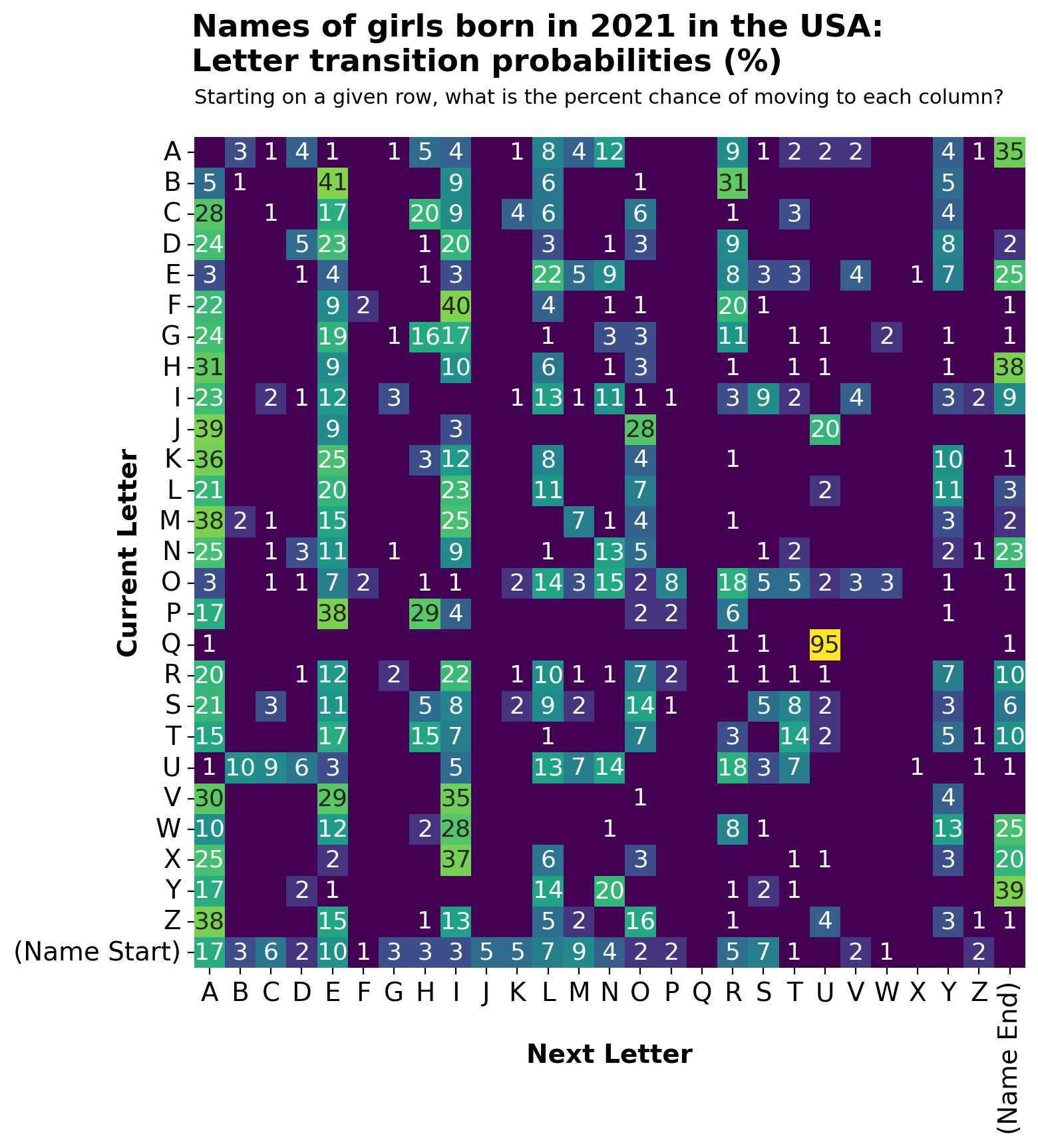
 Transition probabilities (shown as percentages) between successive letters in the names of girls born in 2021 in the USA [OC]
Transition probabilities (shown as percentages) between successive letters in the names of girls born in 2021 in the USA [OC]kilopeter OP t1_j6adleq wrote
Interpretation [EDITED]: Take all the names on U.S. Social Security card applications for girls born in 2021. Scan through the names one letter at a time, accounting for the start and end of each name. Count how many times each particular letter is followed by every other letter in the alphabet. Finally, convert your counts to probabilities (technically, percent chance = probability * 100%) to give the chance that any given letter in a name is followed by every other possible letter (or by the end of the name). This visualization summarizes the resulting transition matrix.
Background: The ongoing explosion of generative AI systems got me thinking about the statistical structure of words, and of given names in general. I started with the fairly basic idea of treating the sequence of characters in given names as a Markov process, i.e., the next state is chosen randomly according to transition probabilities that depend only on the current state, not prior states.
Code: https://github.com/pjleimbigler/baby-name-analysis
Data: https://www.ssa.gov/oact/babynames/limits.html
Generating new "names": The letters in given names are pretty clearly not generated by a Markov (memoryless) process. However, it's fun to assume the Markov property anyway and see what "names" fall out of the transition matrix.
To iterate through the transition matrix manually using this viz, follow these steps:
- Start with the bottom row,
(Name Start). - Each number in your current row is the percent chance (probability * 100%) of choosing your name's next letter as the letter corresponding to each column.
- Randomly choose the next letter of your name, based on the percent chances in the current row.
- The letter you just chose now becomes your "current letter." Look up its row.
- Repeat Steps 2–4 until you land on the last column,
(Name End), which signifies the end of your generated name.
This yields some hilarious yet often oddly plausible names, such as: Silian, Slya, Lialy, Maerollia, Chla, Zalah, Lay, Lonanaadievayle, Zoralepa, Peiemophaly, Dralesa, Wiada, Miea, Giaberosh, Bisodiaremanninenn, Seelanida, Einnn, Penasoetimala, Hepanelei, Mia, Mierolynakynisayloloneeloa, Sargandniamilida, Eldyanempe, Pinahanariloma, Alian, Melivevilllohayasisa, Olyna, Die, Mizaramiceatelyalla, Jon, Adelun, Cesklienzolena, Zolyryn, Ema, Leyla, Aclan, Bra, Maeylises, Bryn, Khiemi, Sly, Annnlis, Aisyasa, Xily, Kara, Handanaria, Manla, Pama, Heyanama, Eylisidr, Brah, Llee, Anelerynaevega, Ayatryalofa, Mediza, Caniesty, Oliceeelys, Sannllora, Dassole, Sonnasse, Mmatarieleteyneroselasylin.
mikeholczer t1_j6agh1p wrote
Following those rules the most likely outcome is “A”
kilopeter OP t1_j6b6t8c wrote
Yep. "A" is the most frequent letter at both the start and end of names in the dataset I used (girls born in 2021 in the USA).
mikeholczer t1_j6b7fim wrote
My point is your interpretation is flawed, because the most likely outcome of it is very far from the actual most likely name.
kilopeter OP t1_j6b9h0h wrote
Oh, absolutely: the fact that this Markov assumption yields nonsensical names shows that the sequence of letters in given names are not generated by a Markov process. (The next character depends very much on previous characters, not just the current one.)
But this visualization does accurately present the relative frequencies of character transitions in actual names. Using these frequencies to generate Markov chains of characters and calling the results names is a fun diversion whose results I found entertaining.
mikeholczer t1_j6b9was wrote
Yeah, I think the display of the data is interesting, I just think what you wrote about it is misleading.
kilopeter OP t1_j6banxn wrote
Oh? What part? I specifically qualified my interpretation with "want to reflect typical between-letter patterns of US girl names."
That's the point of using this viz to generate new names: generating character strings with totally realistic letter-to-letter transition probabilities is not enough to yield plausible names, or names which already exist. The generated names are often bizarre or excessively long, yet their character transition probabilities exactly reflect that of the real names in the input dataset.
mikeholczer t1_j6bb50x wrote
If one follows your steps, the most common outcome is one letter and there has no between-letter patterns which clearly doesn’t match the between-letter patterns of the source data.
kilopeter OP t1_j6bbmom wrote
It does if you include the placeholder "characters" for the start and end of each name! The most probable "name" A represents three tokens: [name start], A, [name end]. And if you generate many names using the transition matrix, you will indeed observe that the frequency of [name start] -> A and A -> [name end] matches the corresponding frequencies in the source data.
EDIT: on reflection, I agree with you. I should introduce the heatmap as a description of transition probabilities, but should avoid walking the reader through using the transition matrix to generate new "names." I should separate the topic of generating new names using the transition matrix under the (invalid) Markov assumption as a diversion. Thanks for pointing out the flaw in my explanation. I'll edit my top level comment when I have a chance!
globglogabgalabyeast t1_j6bwjuz wrote
Did you already edit it? Cause I never got the impression that you were implying this process would lead to realistic names
kilopeter OP t1_j6ea6zq wrote
Nah, I'm only just now getting a chance to edit my top-level comment. Thanks for throwing in your vote! I feel like I can reword the "interpretation" part better to avoid any possible misinterpretation.
ghostfaceschiller t1_j6bz394 wrote
Have you done this analysis on any other corpora? I’d be super interested to see it on something like the Google Corpus (or a reasonable subset of it). Or BNC, etc
kilopeter OP t1_j6ecjw9 wrote
I haven't, but good point. The code to count transitions between characters is very straightforward (well... I wrote mine without worrying about performance issues), and in principle could be packaged as a lightweight web app or even a JavaScript-powered static site and accept any text corpus uploaded or linked by the user.
ghostfaceschiller t1_j6ej1pw wrote
I recently put together a repo of character frequency analyses, bc they can be really useful when designing keyboard layouts. So I have an eye out rn for interesting ways to look at and visualize the data. I think this particular instance is probably too limited to be useful for keyboard layouts, but if you do anything more please let me know! It’s one of the more interesting visualizations I’ve seen so I’d love to include/link it
kilopeter OP t1_j6eq2tj wrote
Oh nice, I'll let you know!
Viewing a single comment thread. View all comments