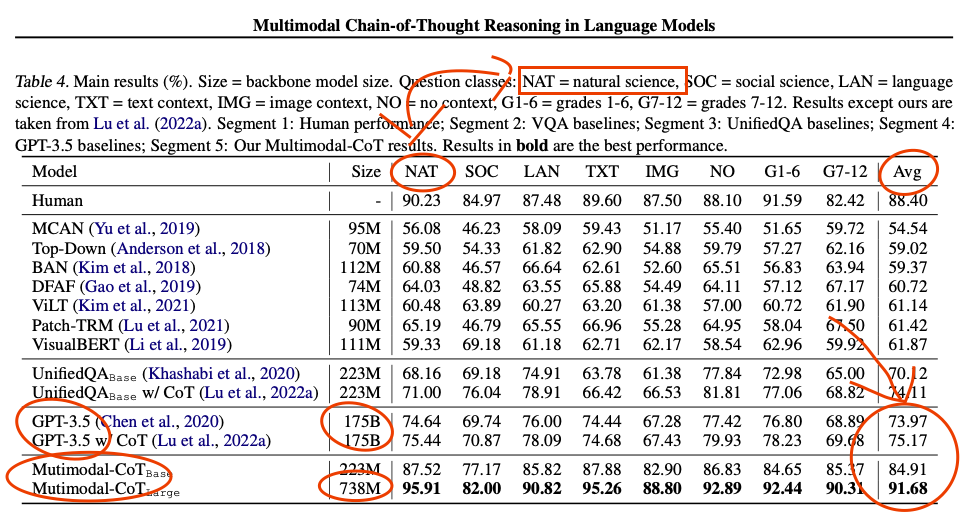
 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]turnip_burrito t1_j9j8dmm wrote
Reply to comment by Spire_Citron in What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions] by Destiny_Knight
One critique I saw in another thread is that this was "fine-tuned to hell and back" compared to GPT-3, which could explain some of the increased performance, so take that as you will.
Spire_Citron t1_j9j9n46 wrote
Fine-tuned towards taking these sorts of tests, or just more optimised in general?
duboispourlhiver t1_j9ji6qe wrote
Yes, the risk is to be over fitted for this test. I've read that too about that paper but haven't taken the time to make my own opinion. I think it's impossible to judge if this benchmark is telling or not about the model's quality without studying this for hours
Spire_Citron t1_j9lcgc9 wrote
If it was specifically taught to do this test, it is much less impressive because it probably means it won't have that level of intuition and understanding with other tasks.
monsieurpooh t1_j9ni0aa wrote
I'm curious how the authors made sure to prevent overfitting. I guess there's always the risk they did, which is why they have those AI competitions where they completely withhold questions from the public until the test is run. Curious to see its performance in those
Borrowedshorts t1_j9kcmhm wrote
Humans finetune to the test as well.
dwarfarchist9001 t1_j9kpzs8 wrote
Humans don't suffer from overfitting if they train on the same data too much.
skob17 t1_j9kt3k1 wrote
Oh they absolutely do. If the test questions have a slightly different approach, many of the hard memory learning students fail.
Borrowedshorts t1_j9ldhl5 wrote
Yes they actually do.
pinkballodestruction t1_j9m407a wrote
I sure as hell do
Viewing a single comment thread. View all comments