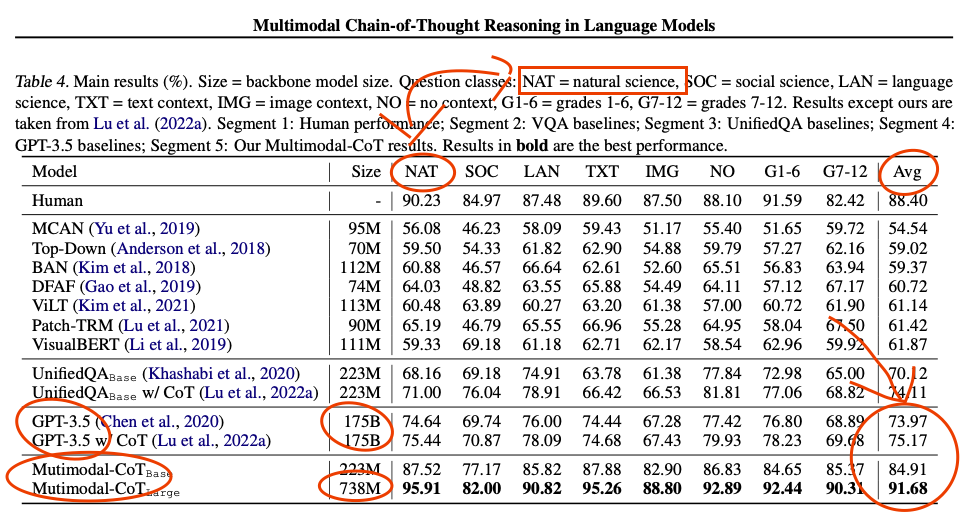
 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]IluvBsissa t1_j9j8ubb wrote
I don't get it. Why are they comparing their model's performance to regular humans and not experts, like every other papers ? Does it mean these tests are "average difficulty" ? I read somewhere that GPT3.5 had a 55.5% score on MMLU, while PalM was at 75 and human experts 88.8. How would this CoT model perform on standards benchmarks, then ? I feel scammed rn.
ertgbnm t1_j9jgoi9 wrote
Read the questions on scienceQA. They are hot and not hot dog type questions
Viewing a single comment thread. View all comments